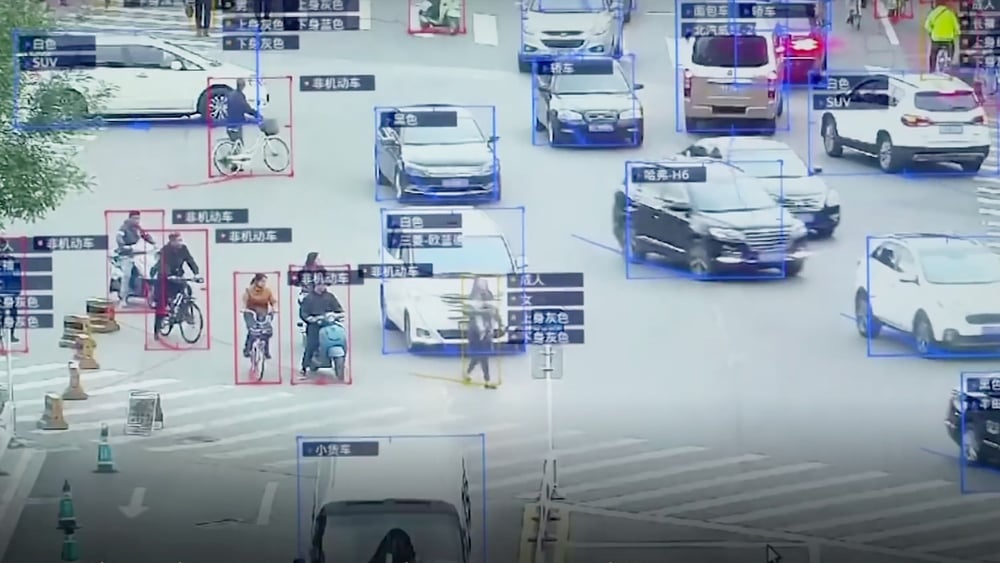
Sept minutes. C’est le temps qu’il aura fallu à la police de Guiyang pour reconnaître, identifier et arrêter le journaliste de la BBC John Sudworth. En décembre 2017, celui-ci s’était prêté au jeu de tester l’arsenal de surveillance mis en place dans cette ville du sud-ouest de la Chine –constitué de caméras à reconnaissance faciale capables de déterminer l’âge, le genre et les principaux caractères ethniques. Les visages filmés par les caméras sont confrontés à la base de données constituée par les photos d’identité et permettent au système d’identifier une personne en quelques secondes. Le programme de sécurité est doté d’une intelligence artificielle capable de lier ces données à celles de véhicules, de fréquentations, et de traquer les déplacements d’une cible de manière autonome. Il est ainsi possible de retracer dans les détails le parcours d’une personne sur la dernière semaine écoulée. Depuis, le système a prouvé son efficacité dans des cas bien plus réels. Selon le Washington Post, un homme soupçonné de «crimes économiques» a été arrêté le 7 avril au milieu d’une foule de 60 000 personnes alors qu’il assistait à un concert.
En un peu plus d’une décennie, la Chine s’est hissée au premier rang des pays les plus surveillés. Son système de surveillance baptisé SkyNet compte aujourd’hui plus de 170 millions de caméras –dont une grande majorité dotée
d’intelligence artificielle (IA). Il est amené à s’étendre dans les prochaines années pour répondre aux ambitions sécuritaires du gouvernement de Xi Jinping. Objectif affiché: multiplier par huit son parc de caméras d’ici à l’horizon 2020.
Mais le système chinois est aussi et avant tout un laboratoire décomplexé, où le respect des libertés fondamentales n’a que peu de poids face aux velléités de contrôle de la société par les organes de l’État. C’est dans la région du Xinjiang, à l’ouest du pays, que le programme de surveillance chinois est le plus développé. Un réseau dense de caméras vidéo, de points de contrôle et d’informateurs humains surveille de près la plupart des habitant·e·s, en particulier ceux d’origine ouïgoure ou kazakhe. Pour Solange Ghernaouti, professeure à l’Université de Lausanne et experte internationale en cybersécurité et cyberdéfense, «les systèmes de vidéosurveillance, de plus en plus intrusifs puisque de plus en plus intelligents et omniprésents, emprisonnent les individus, les tiennent en laisse électronique et les contraignent à opter pour des comportements pas uniquement socialement acceptables, mais normés selon un système politique déterminé.»
L’emprise des autorités chinoises sur ses administré·e·s ne s’arrête en effet pas là. La surveillance de masse «intelligente» s’inscrit dans le contexte plus large de la mise en place d’un système de notation des citoyen·ne·s chinois·e·s selon leur comportement social. Le projet de «crédit social» en cours de développement –et en phase de test– pourra ainsi priver d’accès à certains services les personnes mal notées. Dans le désordre: mauvais payeurs, opposant·e·s politiques, auteur·e·s d’incivilités, membres de groupes religieux non reconnus… Le gouvernement se laisse deux ans pour que les presque 1,4 milliard de Chinois·e·s soient intégré·e·s à ce programme.
Un modèle à exporter?
Pour Solange Ghernaouti, l’Europe n’est pas à l’abri de l’adoption d’un système de surveillance totale. Celui-ci pourrait être justifié par des questions de sécurité, notamment dans un contexte de lutte antiterroriste, et donc accepté par la population. «Nous acceptons l’illusion de sécurité que peut procurer un système de surveillance présenté comme un système de protection. Le glissement de l’appellation ‘système de vidéosurveillance’ vers celle de ‘système de vidéoprotection’ résume à lui seul l’ambivalence de ces systèmes», déclare l’académicienne. Quant à notre capacité à résister à une restriction de nos libertés, la chercheuse se montre sceptique. «La population s’habitue sans résistance, comme elle s’est habituée à l’usage a priori indolore des cartes de crédit pour les paiements en ligne. Or, la traçabilité des transactions électroniques autorise une surveillance et un contrôle social.»
Pourtant, l’implantation d’un système analogue n’est pas pour l’instant près de voir le jour en Europe. En témoigne l’arrêt rendu le 13 septembre dernier par la Cour européenne des droits de l’homme (CrEDH). Cette dernière a jugé que la surveillance de masse opérée par le gouvernement britannique violait le droit à la vie privée et la liberté d’expression. L’arrêt souligne que le cadre dans lequel les services de renseignements électroniques interceptent les communications de citoyen·ne·s britanniques était insuffisant pour garantir le respect des droits fondamentaux.
À l’origine était la masse
«La surveillance de masse est facilitée par les technologies du numérique car chaque activité, chaque connexion, chaque usage laissent des traces. L’empreinte numérique des utilisateurs est récoltée, stockée, croisée avec celles issues d’autres sources (téléphone, caméra, navigation web, paiement en ligne)», explique Solange Ghernaouti. Une étude de l’International Data Corporation (IDC), une entreprise américaine spécialisée dans la réalisation d’études de marché dans le domaine des technologies de l’information, prédisait en 2017 que le volume de données sera multiplié par huit d’ici à 2025. Mais au-delà du volume, c’est aussi la nature de ces données qui est amenée à changer. Si, à l’heure actuelle, la majorité des informations stockées a trait au divertissement (photos, vidéos), celles collectées à l’avenir seront «de plus en plus critiques, au sens où elles sont le support d’activités humaines considérées comme vitales».
À chacune de nos activités en ligne, des dizaines de milliers de données sont collectées et assemblées pour former de gigantesques ensembles, que l’on appelle communément Big Data, «mégadonnées» ou «données massives». Du fait de leur caractère complexe et surabondant, elles doivent être traitées avant de pouvoir être exploitées. C’est à cette étape qu’interviennent les intelligences artificielles, capables de faire le tri dans cette montagne d’informations avec un certain degré d’autonomie. Mais ces machines ne naissent pas intelligentes, elles doivent apprendre.
Limites de l’apprentissage autonome
Prenons l’exemple fictif d’une ville qui cherche à faire baisser son taux de criminalité. Pour ce faire, elle fournit ses statistiques au sujet des lieux, dates et heures, types d’infractions à une IA. Sur la base de ces données, cette dernière doit prédire dans quelle zone de la ville envoyer des patrouilles de police. Sauf que cette ville a une histoire chargée, et ses forces de police ont longtemps concentré leur action dans des zones à forte concentration de minorités ethniques et religieuses. Un algorithme n’étant pas capable d’identifier ce biais, il concentrera ses efforts sur ces mêmes zones. Et le cercle vicieux s’enclenche : plus de présence policière amènera plus d’arrestations qui ne feront que confirmer le bien-fondé des prédictions de l’IA.
Pour qu’une machine puisse apprendre par elle-même, ses programmateurs lui fournissent des quantités énormes de données. Plus l’ensemble de données est grand, plus les résultats seront affinés. On parle alors de deep learning, ou d’apprentissage en profondeur. Des algorithmes analysent ces données à la recherche de schémas qui se répètent, de modèles, pour ensuite être capables de raisonner ou de prédire un événement. «C’est à l’étape suivante du processus, soit lorsque l’algorithme est amené à prendre des décisions, qu’un apprentissage biaisé peut révéler ses failles», souligne Sherif Elsayed-Ali, directeur de recherche chez Amnesty International. En effet, la sélection du corpus de données sur lequel sera basé l’apprentissage influencera le fonctionnement de l’algorithme. En d’autres termes, rapporté à une échelle humaine, cela équivaut à dire que nos connaissances dépendent des professeur·e·s que nous avons eu·e·s.
L’apprentissage automatisé soulève un autre problème, celui de son opacité. Le deep learning utilise des réseaux formés de couches successives. Une première opération fait correspondre les informations reçues à l’entrée et des interprétations à la sortie. Une seconde opération se basera sur les conclusions de la première pour en tirer d’autres, et ainsi de suite. Impossible de retracer la façon dont la machine fait correspondre les informations qu’elle reçoit et les décisions qu’elle prend. Qui doit être tenu responsable des choix de la machine ? Comment réparer une éventuelle erreur s’il est impossible de comprendre pourquoi elle a été commise ? Pour combler ce manque, il existe un courant parmi les entreprises actives dans le domaine pour développer des IA explicables.

Rétablir le lien avec les droits humains
Il y a plusieurs domaines dans lesquels ces mécanismes de prise de décision automatisée sont appliqués –ou le seront dans un futur proche. Ils ont potentiellement un impact important sur les droits fondamentaux. Est-il souhaitable de laisser à une IA le choix de décider si une personne remplit les conditions pour être couvert par une assurance maladie, si elle est éligible à un prêt ? «Les effets discriminatoires de l’IA sur les droits humains peuvent avoir une portée considérable et être dévastateurs», analyse le chercheur d’Amnesty. Mais ils ne découlent pas pour autant automatiquement du fait que les décisions sont déléguées à des machines, tempère Solange Ghernaouti : «Les erreurs ou dérives d’une intelligence artificielle sont avant tout des erreurs humaines, automatisées à grande échelle.» D’où l’importance d’un apprentissage «impartial», sans parti pris. Selon Sherif Elsayed-Ali, il existe trois défis principaux à relever en matière d’IA pour garantir le respect des droits humains. Tout d’abord, détecter et corriger les biais ou les partis pris, par exemple en s’assurant que des préjugés –raciaux, religieux, de genre, et autres– sont absents des processus de l’IA. Engager la responsabilité des utilisateurs, ensuite, ce qui équivaut à tenir les employeurs responsables des décisions prises par leur IA de la même façon qu’elles le seraient pour un employé humain. Enfin, renforcer ces contrôles dans les domaines qui ont un impact potentiel sur les droits humains.